


dfscore 2.0
![]()
dfscore 2.0 is here! dfscore 2.0 is a much improved and completely rewritten version of dfscore that I started working on a couple of years ago. The dfscore system is a realtime dynamic score system built to display a variety of musical material over a local computer network. The primary motivation for building the system was to allow for a middle ground between composition and improvisation.
But before I get into all of that, here is a video showing the latest version along with its premiere at the Manchester Jazz Festival:
Background (dfscore 1.0)
The original version of dfscore was built in Max, and although it was used in some performances and workshops, it was clunky, hard to compose for, and limited to computers that could run Max.
Read more about the development of the original dfscore system:
Before beginning to program dfscore I researched three software systems similar to what I had in mind: the Noise Quartets by Eric Lyon, the iScore system by Andreas Weixler, and Shackle by Robert Van Heumen. At the time two of these systems were not openly available or well documented so I wrote the composers/programmers in order to view their code. Two of the systems were purely text based (Shackle and Noise Quartets), whereas iScore used images and some short videos to communicate information (Weixler and Chuang 2012). All three had relatively small interfaces and were highly specialized in their design and implementation. After looking at these implementations I decided to address many of what I felt were shortcomings in their systems for my intended use in music. I also added a more open feature set.
During my initial research I did not encounter INScore, which is a comprehensive augmented musical score, to use their terminology (Fober, Orlarey, and Letz 2012). INScore solves many of the problems I was trying to solve with dfscore, but is primarily a score displaying platform, rather than a compositional system, which is what dfscore would develop to include. The focus of INScore was also geared towards interactive scores in a traditional composer/performance paradigm, rather than focusing on improvisation like dfscore, or Noise Quartets and Shackle.
The dfscore system is comprised of two main parts. The first is the dfs Performer application. This is the rendering engine, which is compartmentalized from the rest of the code. The idea was to have a black box that would receive messages and display a variety of materials independent of context. This compartmentalization serves two purposes. The first is developmental, as I can focus all of my energy on producing a rendering engine that can display whatever it is I want to display, independent of what it takes to generate those messages. The second is ease of use. The dfs Performer application is the client in the host/client model of networking, so having it isolated from what the host is doing makes it easier to set up and use.
The interface for dfs Performer went through many iterations and was workshopped with a variety of performers before stabilizing in its current implementation. The display occupies the whole of the computer screen by adapting to fill the screen space. The main display section occupies the whole of this window with a couple of overlays. The most prominent overlay is the picture-in-picture section used to display upcoming material. There are additional functional overlays like the current place, countdown, and flashing sections.
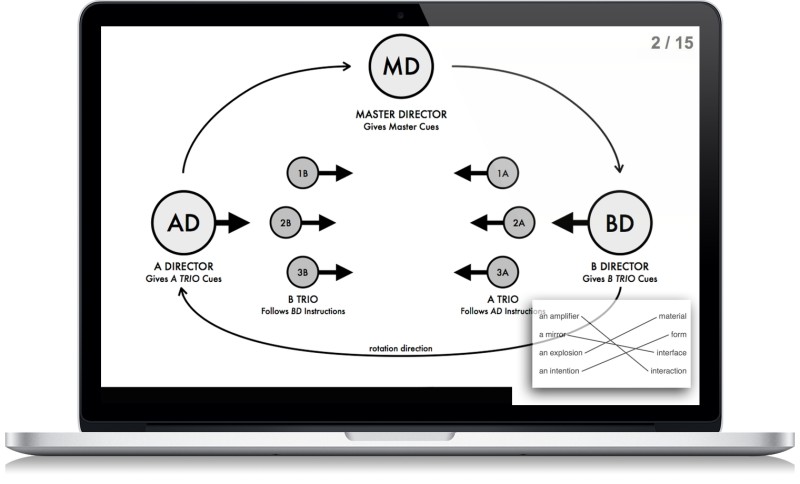
All of these elements were designed with a minimal aesthetic so as to let the content be the main visible feature. Having such a large and simplistic interface makes the application easy to use in a performance environment and requires very little additional learning on the part of the performer.
The dfs Performer application is built to display three main types of messages: text, notation, and images. Each one of these is built as an independent submodule and is robust in its implementation. The text display can take text strings ranging from 1 to 200 characters in length and will auto-size and auto-align depending on the length of incoming text. The notation display is based on Bach externals and allows for client-based configuration depending on the instrumentation used. Each performer can pick their instrumental transposition. Furthermore, the clef and the incoming notation messages will be formatted locally, making it very easy to compose material without having to worry about specific instrumentation.
The second part of the system is the OSC message formatting specification. Rather than building an application to try to account for every possible compositional approach, the idea was to devise an intuitive and thorough messaging system that enables the composer to generate however they like. This approach allows for maximum flexibility in exchange for an initial learning curve. The included patch for ialreadyforgotyourpussy.com is an example of such an implementation. The messages in that patch are stochastically generated and make extensive use of the hiding functionality of most of the display features.
This is a rough sketch of the OSC message specification:
dfscore message spec
==================================
Top level:
/dfscore = top OSC namespace
Next level:
/dfscore/score = all messages dealing with notation (two way)
/dfscore/setup = all messages dealing with tech/setup (two way)
Utility level:
/dfscore/score/info = general info about piece (composer, title, instrumentation, performers, tempo, duration, dfs version) (one way)
Sending messages:
/dfscore/score/performerXX/main/text {message} = main message format
…/performer0 = all performers, /performer1-xx = individual addresses
…/main, /mini, /countdown, /section, /line, = display types
…/text, /notation, /graphic, /lcd, /aux = message types
Utility message types:
hide and unhide sent to any display type will hide and unhide it
() clears the contens of the main/mini display windows
Receiving messages:
/dfscore/score/feedback/performerXX = for musical feedback from performers
The dfscore system is still in development but functional for my own use. Once the feature set is stabilized I will distribute the system along with thorough documentation and a couple of examples of score generation to allow other composers to use the system and afterwards hopefully gain some valuable feedback on implementation and design.
During the development of the original dfscore system Richard Knight helped me with some of the DHCP server stuff. When it came time to improve the system I thought he would be the perfect person to bring in, given his knowledge and background with web-based art/music/tech. And boy was he!
As part of a Jazz North commission Richard rebuilt dfscore from the ground up to work completely in a web browser. This instantly expanded the types of devices it could work on. dfscore could run on any device that had a browser, including iPhones/iPads. This also opened up the possibility for a broader range of dynamic score types. The original dfscore focused on static panels of text, notation, and images. However, using a browser as the rendering engine meant a dfscore could be anything that can be displayed in a browser. So your dreams of having a Facebook score, embedded YouTube score, and interactive javascript graphics can finally come true!
Richard also refined how composers work with the system. He restructured the composition language to be written in javascript inside a simple XML container. He created a wiki with a dfscore API and a composition tutorial which walks new users through how to create pieces for the system. Within the javascript spec, the code was structured around Roles (dynamically assignable roles within the composition) and Events (the panels which are displayed to the performer), allowing for a much more open and dynamic compositional approach. He then condensed each composition into a package containing all of the necessary code and assets so that it can be easily shared and loaded.
The hardware that runs the system also changed with this update. dfscore now runs on a Raspberry Pi, meaning no individual computer needs to run as the server for the system. This headless system also works as a Wi-Fi hotspot, so performers can simply power up the Raspberry Pi and join the dfscore server/network with their phones, without a laptop involved at all.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Development (dfscore 2.0)
Since I didn’t program the 2.0 version, I asked Richard a few questions about why he chose the specific technologies (Javascript/WebSocket/nodes.js), what his development process was like, and what issues he ran into along the way. The following is what he had to say:
dfscore uses the node.js platform (acting as a standalone Javascript interpreter) as a server and web browsers as clients. Because all modern browsers can interpret Javascript, this combination means that all of the application logic can be written in one language. In addition to this, styling, layout, and templating is applied using standard HTML and CSS.
The dfscore server software is designed to run on a Raspberry Pi with wired and wireless LAN interfaces (but has additionally been tested on Mac OS X and Debian). The Pi setup involves using hostapd (wireless access point server), dnsmasq (simple DNS server), isc-DHCPD (for assigning IP addresses) and network bridging between wired/wireless interfaces.
Read more of Richard Knight’s commentary on the development of dfscore 2.0:
All of the development dependencies are open source, and given the open source background of dfscore, it is appropriate for future iterations of the software to remain open source. Additionally, this benefits composers and developers who may wish to extend the software further or create forks of the project to facilitate their specific requirements.
Although based on the original Max/MSP version, dfscore was rewritten from scratch with little underlying technical semblance to the original. However, visual and conceptual correspondence were desired to allow for an operational continuity of the system from a performer’s perspective, as presentational and conceptual aspects were deemed appropriate in the existing version.
Some of the fundamental technical changes were applied as part of the redesign process, whereas many others were necessary due to the browser-based migration. An example of the latter is the change of the underlying transport protocol from UDP to TCP, as UDP is technically impossible in a browser.
In the Max/MSP version, compositions were defined as Max/MSP patches, as was the system itself. This posed a complicated hurdle for the design/development processes and incurred a period of extensive research with little precedent around the specifics intended. With the criteria for the composition language being something as powerful and extensible as Max/MSP, with an equal or more permissive learning curve, a couple of iterations of a new dynamic and reactive compositional ‘language’ capable of determinate and indeterminate scores were tested. Initially
As compositions were arbitrarily defined in the Max/MSP version, anything representable could be used in the context of an event/pane/performance instruction. As part of the redesign, in order to rationalise a pragmatic compositional approach, a finite number of types were incorporated into the system known as ‘Events’. These include the following:
- TextEvent – Facilitates the display of a text string, centred and adjusted to the largest font size deemed feasible for the length of string.
- ImageEvent – Shows an image as contained in the directory associated with the composition, centred on screen.
- ScoreEvent – Accepts VexTab markup to display music notation using the VexFlow engraver.
- ScriptEvent – Allows for the display of any arbitrary information using Javascript, assisted by jQuery. Some examples of this include animated events and the rendering of dynamic SVG graphics.
The initial research into defining the dfscore composition language was based around an XML document which also encapsulated scriptable components using Javascript. This presented a point of compromise between functionality and a smooth learning curve. However, extensive testing of the specification proved that while the specification was effective and easy to implement for intermediate and simple scores, advanced scores featuring heavy emphasis on arbitrary scripted elements and strongly indeterminate scores were disproportionately complicated to achieve. As a result, research and testing of a pure Javascript composition language was carried out, extending upon the scriptable elements already defined in the existing XML specification – ultimately resulting in a superset of Javascript. This allows for the composer to leverage the power and documentation of an existing language with a similar or perhaps fundamentally even simpler syntax than the XML specification. Most definitions and declarations use constructor functions (prepended with “new” at creation time) with the aim of helping to contextualise the creation of objects and actions. Aside from these constructor functions, there are a few core functions including
perform()
which delegates the performance of a particular event to a role. Another important function is
global()
, which executes code in a global space before performance time, as opposed the normal mode of operation which is to evaluate code on a per-role basis at performance time.
Evaluation of score code occurs in a ‘threaded‘ context which is unusual for the event driven nature of node.js. This is assisted by the ‘fibers‘ module which offers coroutine support for a ‘traditional’ approach to multithreading, with the objective being the tightest synchronity between the different role computations.
The browser/server transport uses JSON (JavaScript Object Notation) over websockets. While the previous dfscore used OSC to trigger assets already present on the client, all asset data is now cached by the clients where appropriate. Initially, this involved the caching of all event data determined to be used by a given role, with undetermined events cached one-ahead (at the time of the preview being displayed, if applicable). However, for some browsers/clients during testing this appeared to cause problems with load due to high numbers of cached elements in the DOM, and as a result the production version for Manchester Jazz Festival used a simpler one-ahead caching model. This appeared to be fine although large resources such as images did have a slight delay in being loaded to the preview display, if shown.
Transitioning the system to a browser based front-end platform has a number of advantages, mainly portability. dfscore now has the capacity to run in any environment under which a modern web browser can function (effectively all consumer operating systems across desktop, tablet and mobile devices).
Also, although the previous dfscore was open source as mentioned above, Max/MSP is only available freely as a runtime version, limiting further development and forking to owners of a licensed copy. The shift to node.js/browser frontend has the advantage that the entire software stack for dfscore can now employ free software, also potentially reducing the hardware requirements to run the software smoothly.
However, there are many hurdles and issues with using browsers for realtime applications with the level of accuracy required by dfscore. One central issue around using them is that only TCP connections are supported within browsers (UDP is usually used for realtime connections due to having no handshake/error checking, whereas TCP has a round-trip handshake which ensures integrity but can in some circumstances increase latency).
Websockets are really the only option for realtime bidirectional communication (instigated by either client or server) in browsers at current – traditional browser functionality implies that the browser initiates the connection/sends a message and waits for a response from the server. dfscore requires that the server initiates/sends messages to the browser. Using the traditional approach, the browser would ‘long poll’ the server periodically and take action upon a message being ready. This is inappropriate for realtime communication as it means the client has to continually check for changes, which increases network/client overheads/redundancy and reduces the reactiveness of the client to the resolution of the polling.
The websocket protocol attempts to alleviate the situation for realtime applications by allowing connections/messages to be initiated from either client/server and thus removing the requirement to poll for changes. However, there are still some issues in creating time-critical applications with websockets as TCP is unavoidable without browser extensions or platform-specific addons. One of the concerning aspects of using TCP in realtime is Nagle’s algorithm – which conserves bandwidth by holding on to packets and ‘bursting’ them in one go. Fortunately most TCP implementations typically have a parameter (often ‘tcp_nodelay‘) which circumvents this algorithm. Nevertheless Nagle’s algorithm occurs at a low level in the TCP stack and it is hard to evaluate the efficacy of toggling it without relatively low level network analysis.
There is no standardisation across browsers to the level ideally required. One of the major problems encountered was related to timing (each browser rendering engine has its own method of creating timed delays as implemented by Javascript’s setTimeout function). For example, (certain/current versions of) mobile Safari appear(s) to ignore setTimeouts of a period less than 10ms. This is not well known/documented as most current ‘realtime’ applications of browsers are well above the resolution required for a desirably sample-accurate performance system. Thus cross-browser stability and interaction becomes a further research area as emerging technologies are developed.
This aspect leads on to the point that quite a few features of HTML5 are not yet standardised – in addition to possessing specific implementation patterns for particular browsers (therefore requiring ‘platform’-specific code in some areas – particularly with CSS styling), and suffering from minimal documentation and buggy/inconsistent actual functionality even between recent differing versions of the same browser.
CSS transitions are a new way of implementing animation/transition effects which negate the need for being concerned about timing inconsistencies of Javascript based animation. The core animations in dfscore include the progress bar at the bottom of the screen, green pulsing of the main event display area, and red pulsing of the preview count-in. Initially jQuery animations were employed to present the animations, but these were found to potentially be computation heavy, in some circumstances speculatively affecting stability/smoothness and timing. CSS transitions are a way of accomplishing the same result with pure CSS, in most circumstances providing smoother rendering and greater efficiency, but still depending on the specific browser/OS implementation thereof.
An experimental feature to ‘record’ the performance of compositions has been incorporated which is intended to be replayed in a future ‘dfscore light’ development which will permit embedding in pages and replay without a server.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Commentaries (Implementation)
Several composers (Anton Hunter, Richard Knight, Pierre Alexandre Tremblay) have written pieces for the dfscore system. I’ve asked all of them to write something about their pieces. What follows is their commentary, along with the commentary for my piece.
Rodrigo Constanzo – Hands
The compositional process for Hands started with some reflection on the previous dfscore pieces I’d written (pitchy, demo piece, ialreadyforgotyourpussy.com). By far, the most effective piece was ialreadyforgotyourpussy.com. It was also the most open, materially speaking, since the bulk of the compositional process focused on structure and memory. I felt I had over-composed and over-prescribed the pieces in the premiere so I wanted to avoid that moving forward. Having used the system for several pieces/rehearsals/performances I had discovered a lot about the performance practice of using a system like this in context, and wanted to apply that knowledge to the new piece.
Knowing all of this I started conceiving ideas for the system. I wanted to have several open sections and incorporate space/silence, but I also wanted the piece to have a sonic and structural identity. I eventually settled on four types of Events spread across three Roles.
The defined Roles:
- Drums/Bass – as a rhythm section
- Melody – winds, guitars, or winds + guitars
- Feedback – mixer + flute
The defined Events:
- High/Descent – a high descending figure played by the Melody role
- Heavy/Tight – a low syncopated groove played by the Drums/Bass role
- Memory – a stored and recalled memory for variable individual performers (always recalled as same performers)
- Open – a freely improvised event for variable individual performers (different each time)
Within these blocks of material, which are dynamically orchestrated/distributed, there are some simultaneous events, which serve to break up some of the overall blockiness of the system. The Heavy/Tight event can have sub-events happen within it, defined as High/Descent (a faster/shorter echoing of the High/Descent figure) and a Feedback dyad event (both feedback instruments fading in/out a static pitch). These available Event and Role types laid the conceptual and material foundation for the piece.
Rather than having the Events randomly distributed throughout the piece, the whole piece uses Gaussian distributions to determine the order, duration, and instrumentation in each Event. In addition to the Gaussian distributions there are some hard-coded structures and limits in the piece. For example, the High/Descent event always begins the piece and can only happen either two or three times total (randomly determined). This combination of weighted randomness along with tuned constraints gives the piece an identity but allows it to be flexible and dynamic.
Here are the global parameters for the overall piece:
var parameters = {
roles: ["Flute/Feedback", "Saxophone", "Guitar1", "Guitar2", "Bass", "Drums", "Mixer"],
pieceDuration: [20, 35], // piece duration [events]
eventProbability: [20, 25, 35, 20], // event type probability [High/Descent, Open, Memory, Heavy/Tight]
}
Here are the parameters for each Event type:
var parameters = {
highDescent: {// high/descent variables
amount: [2, 3], // amount of High/Descent [events]
duration: [5, 10], // duration of High/Descent [seconds]
ratio: [0.6, 0.9], // ratio between High and Descent [ratio]
inst: [50, 20, 30] // instrumentation percentage High/Descent [wind, guitar, wind+guitar]
},
open: {
performers: [1, 7, 2.1, 3], // performer amount of Open [min, max, gaussMean, gaussSpread]
duration: [8, 18] // duration of Open [seconds]
},
memory: {
performers: [1, 7, 3, 2.1], // performer amount of Memory [min, max, gaussMean, gaussSpread]
duration: [4, 15], // duration of Memory [seconds]
total: 3 // total amount of Memories ["A", "B", "C"]
},
heavyTight: {
amount: [2, 3], // amount of Heavy/Tight [events]
duration: [10, 25], // potential duration for Heavy/Tight [seconds]
stabDescentAmount: [0, 4, 0.6, 1.2], // amount of Stab/Descent [events[min, max, gaussMean :[as ratio), gaussSpread]]
stabDescentDuration: [1, 3], // duration of Stab/Descent [seconds]
stabDescentInst: [50, 20, 30], // instrumentation percentage of Stab/Descent [wind, guitar, wind+guitar]
feedbackDyadAmount: [0, 3, 0.8, 0.6], // amount of Feedback/Dyad [events[min, max, gaussMean :[as ratio), gaussSpread]]
feedbackDyadDuration: [3, 8] // duration of Feedback/Dyad [seconds]
}
The information that is displayed to the performers is purely text, showing only the name of the event, or in the case of a Memory event, a letter indicating which memory is being logged/recalled (A/B/C). Prior to the rehearsals I verbally described the general idea for each Event, purposefully not being too specific with the instructions. I want(ed) the contents of the events to remain fluid and reactive to the improvisation that they are surrounded by, and verbally communicating a general idea encourages that.

After coming up with the probabilities, distributions, and constraints, the piece was tested throughout several rehearsals in order to fine-tune the variables. This fine-tuning process has been central to the compositional process of all of my dfscore pieces. There is an interesting creative area between composition, algorithm, and improvisation that Sean Booth (of Autechre) describes, in discussing the creative working process, as, “[It’s] difficult to say what’s composition and what’s algorithmic, when you define the algorithms that tightly, and we enjoy that grey area” (Zaldua 2015).
During the rehearsals for Hands, as well as the other pieces we performed, I became aware of certain tendencies seemingly inherent to the system. There is a tendency for timing to end up being inadvertently correlated with trajectory. As an event would near its end most performers would freeze their Material contributions (to borrow a term from my improv analysis framework) and simply apply a trajectory to their established material by getting faster/busier/louder. This tended to overemphasize the moments of transition in a predictable and generally uninteresting way.
To combat this I’ve conceived several exercises that I will test out during the next dfscore rehearsals. Here are some of them:
- Playing only changes/beats – to tighten up general synchronicity
- Avoiding artificial trajectories – several drills to curb the tendency outlined above
- Exploring dynamics – amplifying ensemble dynamics when working with block form
- Listening “off screen” – focusing on the material instead of the form (which is the system’s main concern)
- Importance of the downbeat – exploring orchestration and relation to the prior material
- Importance of the upbeat – creating a sense of connection without being the connection itself
- Memory in improv – expanding on how memory works in pieces like Zorn‘s Cobra and ialreadyforgotyourpussy.com
Another issue to deal with in large ensemble improvisation is coincident fetishism, where things that are probabilistically unlikely to happen are overemphasized musically. This leads to having moments of unintentional or unexpected rhythmic, melodic, or harmonic synchrony treated like musical gold. Events that should be fleeting are repeated, ornamented, and exaggerated, generally to the disservice of the music. These moments are harder to create specific exercises for as they do not happen often. I will conceive some Battle Pieces-like mini-games to deal with the rare occurrences but discussing the issue when it appears in rehearsals will be a short-term solution to this problem.
Agency is another interesting factor in dfscore pieces. In pieces like Hands and ialreadyforgotyourpussy.com the performers’ decoupled agency is critical to their conceptual foundations. The removal of the performers’ ability to choose what memories to log gives those pieces their structural framework and an undertone of improv-etude-ness. But in a general way the dfscore system itself functions as a faceless agent, always watching but never seeing. This centralized agency, though as neutral as I have tried to make it, is something I am still trying to figure out my relationship to, on a conceptual level. Hopefully Erich Fromm wasn’t correct when he described technology as a Golem that “cannot live and remain sane” because it can’t “stand any longer the boredom of a meaningless life” (Fromm 1955).
Even though Richard and I are developing an observer view into dfscore, which would allow viewing all of the performers/roles simultaneously, I have purposefully avoided creating a system where this information would be viewable in a performance setting, via a projection or similar display. Conceptually, as in my performance practice, I don’t want to fetishize an embodied score object, and I avoid as much as possible even having tables or music stands to hold the devices. Due to the networked nature of the system it is necessary for there to be some kind of screen (or eventually haptic) feedback for each performer, but it should be inconspicuous in the overall performance. I don’t want the performance to be about the devices, but rather the type of music that they enable.
Click here to download the dfscore for Hands.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Anton Hunter – Burrowed
My piece Burrowed was written initially for a duo of myself and Sam Andreae on tenor sax. You can hear that version here.
Since then I’ve performed the piece with guitar, cello, flugelhorn and clarinet (with the 265 Quartet), as well as arranging it for saxophone quartet, and in various other duos. I was inspired by reading about William Burroughs‘ cut-ups method of writing, and started thinking about how that could relate to my music. I like the spontaneity of improvisation, and a part of that is not knowing quite what to expect, and I thought this was an interesting way to get some of that into the structure of the piece too.
The idea is that there are 7 numbered two-bar sections, and these can be played in any order as the intro, in time. The improvisation also has 7 numbered pitch collections, and this follows the same order, but moving on cue. The outro is a return to the two-bar sections, this time in a different order. In theory there are many different combinations of how to play this piece (25,396,560 to be precise*) but in practice, it became easier to play it in a set, rehearsed way. On the duo version above we play 1-2-3-4-5-6-7 for the melody and improvisations, and then 7-6-5-4-3-2-1 for the reprise of the melody, and this followed suit for all the other versions too. Utilising Richard Knight’s superior programming knowledge, combined with the VexTab notation, meant that the dfscore system could generate the required written music at each point, taking away the familiarity with one set order and reintroducing the intended randomness.
As you can see from the MJF video above, I still counted in the written sections: this is due to some timing issues between the different machines that are still being worked on. Other than that, a factor of the random nature of the music means that I feel more rehearsal time is needed, both to get the intro and outro sections tighter and for me to work on the pacing of the piece as a whole. I found it a bit difficult to play and move things on via the keyboard controls. I think for the next version I will experiment with using the software to assign different lengths for each of the improvisation sections. This will have the added benefit of a ‘progress’ bar along the bottom of the screen so each player knows how long they’ll be in this pitch collection. This will lose some of the ability to react to the natural flow of the improvising, but I think it’s worth exploring.
*or at least, I think so. There are 7! (that ‘!’ is shorthand for ‘factorial‘ and means 7*6*5*4*3*2*1) different permutations of the melody, and for each of those there would be the same number of options for the ending, but minus one as I’d rather you didn’t just repeat the same thing. So: 7! * (7!-1) = 25,396,560. We didn’t add code to ensure the intro and outro were different, the probability of that happening is 1/7!, or 0.000004%, and I reckon I can live with that.
Click here to download the dfscore for Burrowed.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Richard Knight – Belittling Data Q31
The composition for the Manchester Jazz Festival (MJF) is primarily derived from MJF programme data relating to previous years. Initially the public availability of previous programme data was checked using the Internet Archive‘s Wayback Machine (https://web.archive.org/web/*/http://www.manchesterjazz.com). Unfortunately complete continuity was not available so the region 2003-2011 was settled upon. Although, even in this period the years 2005 and 2009 were unavailable. No attempt was made to elicit the information directly from MJF, rather the composition emphasised public availability (and lack thereof) of this data.
- Year – the year of the event
- Day – the particular day of the festival that the event occurred on
- Venue – the name of the venue which facilitated the event
- Time – the start time of the event
- Duration – the scheduled duration of the event in minutes
- Cost – the price to attend the event
- Artist – the performing artist(s), comma separated if multiple
- Type – whether the event was a music performance (m) or workshop/other non-performance event (nm)
This resulted in 358 separate events recorded across the seven years, which can be seen in the mjfComposer/data/raw.json file as formatted json.
[
{
"Year": 2003,
"Day": 1,
"Venue": "St Ann's Square",
"Time": 1100,
"Duration": 60,
"Cost": 0,
"Artist": "The Latin Jungle",
"Type": "m"
},
{
"Year": 2003,
"Day": 1,
"Venue": "St Ann's Square",
"Time": 1200,
"Duration": 45,
"Cost": 0,
"Artist": "Funky Junky Workshop",
"Type": "nm"
},
{
"Year": 2003,
"Day": 1,
"Venue": "St Ann's Square",
"Time": 1245,
"Duration": 60,
"Cost": 0,
"Artist": "Eclipse Saxophone Quartet",
"Type": "m"
}
]
The mjfComposer (https://github.com/1bpm/mjfComposer) scripts were created to assist in processing the gathered data to a more abstract collection attuned for compositional use. Note that there is some redundancy in the scripts, and some calculations/processes resulted in data which was not used in the final composition. The first stage of the processing was to determine the artists associated with each event and to look up a number of search terms associated with each artist’s name using Google. Rooted in good humour, and taking some influence from cultish internet phenomena like the OS Sucks-Rules-O-Meter (http://srom.zgp.org/), the process aimed to gauge hesitantly trustworthy levels of popularity and musicianship for each of the events. The exact process can be seen in mjfComposer/lib/jazzometer.js (and is launched from mjfComposer/generateComposition.js, which adds the search results to raw.json, creating source.json).
[
{
"raw": 2,
"jazz": 818000,
"albums": "1 result",
"live": "1 result",
"review": 2,
"gigs": 320000,
"sucks": 137000,
"rocks": 437000,
"not jazz": 2430
}
]
Due to the high frequency of search queries (if used from the same originating IP) the script regularly got banned by Google and thus an ‘abuse workaround’ was incorporated which requires some manual intervention.
After the gathering of search results, the main body of compositional processing occurs in mjfComposer/generateComposition.js, which takes source.json and creates composition.json, which is then directly used by the dfscore composition at runtime.
At the core, this script translates the event times/durations to a decimal representation so that they can be scaled to the length of the composition.
[
{
"roles":["Flute/Feedback"],
"duration":29480.55,
"event":"notes",
"notes":[
["green",0,0.016751269035532996,0.7238095238095238],
["green",0.08130081300813008,0.008375634517766498,0.36000000000000004],
["green",0.11788617886178862,0.016751269035532996,0.7987978666666667],
["green",0.1991869918699187,0.008375634517766498,0.36000000000000004],
["green",0.2682926829268293,0.016751269035532996,0.7987792],
["green",0.34959349593495936,0.008375634517766498,0.36000000000000004]
]
}
]
While the original intention was to more intricately represent these possibilities and present multiple interpretations of the data in performance, time constraints imposed by the wider dfscore development and preparation meant that one core representational concept was used in the final composition: the allocation of an individual year of MJF events to each performer and a presentation of synchronised time between the years, with particular agitation emphasis on the overlap of events within a given year.
Consequently, composition.json contains a list of performance instructions of the types ‘notes’, ‘silent’, ‘text’ or ‘curve’. Each was interpreted in the composition.xml file, although ‘curve’ ended up being redundant in the final composition.
The composition script itself takes the processed data in composition.json and determines which of the above types each instruction is. ‘text’ and ‘silent’ merely show TextEvents (with ‘silent’ being a kind of preset text event), but the majority of the instructions are ‘notes’, which relay a group of note instructions to the mjfKit function. Fields denoting the role and duration of the event to be displayed are included with every instruction. mjfKit is a specially designed ScriptEvent which interprets the instructions read from composition.json – displaying note data as simple coloured lines, with weight/height, start/end X and Y points and colour as arguments provided in each note instruction. This was accomplished using simple SVG rendering. As a result of the various processes applied to the data, the note instructions contained within composition.json are numerically specific and considerably unsightly to peruse.

Emphasis was placed on the abstract interpretation of these note instructions in order to allow for the same types of graphical displays to be applicable to varying instrumentation. This resulted in a relatively loose structure for improvising performers that attempts to maintain synchronicity between relative timing in accordance with the source data.
The central impetus derives from the antagonised interpretation of clashing performances in the source MJF schedule data, which are displayed to the performers as yellow ‘notes’, as opposed to well padded (potentially well-planned) performances presented in green and red. Despite limitations on the conceptual development of the performance, there appear to be distinguishing differences in the planning/scheduling between years, which goes some way in confirming the motivational theories behind the composition. These include specifics regarding how the scheduling and perceived popularity of acts has changed across MJF years in correlation to pricing.
The composition merely scratches the surface of analysis-led composition potential from time-specific Jazz Festival scheduling data – and the performance presented a somewhat early developmental angle on the concept. As a result the source data and processing scripts are available at the following URL for further exploration, development and research: http://github.com/1bpm/mjfComposer/
Click here to download the dfscore for Belittling Data Q31.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Pierre Alexandre Tremblay – Multitudes Synchrones
For me, writing for the dfs system brings to the fore the question of what is possible to do (or hard to make happen) in large ensemble improvisation – and the related question of what improvisers are good at doing whilst being directed in a polyphonic manner – in other words, what is worth ‘forcing’ upon them to trigger musical moments which are rare if not impossible (yet fantastic when they happen) in group improvisation.
Obviously, the first appeal is to go around the obvious hurdle of such large group improv: the slowness of the negotiation, either from silence or from messy polyphony, to allow the emergence of strong consensual ideas. This slowness is said to be potentially fun to listen to, and it certainly is to play, but it renders certain musical (sonic and dynamic) ideas nearly impossible, if not highly improbable (i.e. parallelism, both horizontal, vertical and diagonal) I explored the latter in my piece – hence the title – and I thought Rodrigo’s memory piece (Hands) is successful in tackling large ensemble coincident changes.
One can confidently say that in polyphonic coordination of improvisers, even Conduction/Soundpainting is limited, as it only allows a single agent a single gesture, or the “sign/cued sentence” becomes so long that it is long to sync – or the grammar becomes confusing. Therefore I think my piece was a good test to experiment with tight, polyphonic-yet-unified improvisation triggers. On the latter, I was trying what I thought was the over-prescriptive limit of bounded improvisation, like a tight graphic score for a two-streams-multi-voices piece, with permutations of orchestration. I wanted to achieve tight cuts between section, without relying on stylistic clichés, yet having a clear swapping effect for the listener: in effect, a sonic blend between Zorn‘s Naked City and Xenakis‘ orchestral masses.
Obviously, this type of writing relies heavily on what I know I can expected from the improvisers in this group:
- timbral balance – the noisiness requested for the lines is open to interpretation, whilst making a unified group sound object by ear essentially negotiated in the moment;
- grooviness, swagger, in the polymeter counterpoints, which otherwise might sound precious and cute;
- instant triggered solos on top – clearly emerging from the mass, yet not OTT;
It was a fantastic process to write for this group this way. If I was to do it again, I think that the process of writing would have benefited from a longer period between a first and second rehearsal for the 3 composers for whom it was the first time. I am very much a hands-on composer, by opposition to a conceptual one, and I mostly focus on sound and interaction, and legibility for the listener. Therefore, for most of my commission projects, I request time with the musicians, in the writing process, to experiment with ideas/notation/interactions/dynamics, to see how they behave in the reality of the music practice.

I think such an approach with dfscore would have allowed me to try more daring ideas – it would have been probably 5-6 small etudes to see which ones had more musical potential (sonic and interaction and formal). To be even more specific, in this piece, in the A sections I would have tried ranges, durations, and paring of ‘slides’ for better blend, balance and pitch clarity, and for B sections, I would have tried different tempi, as well as the same paring and balance experiments. I would have also tried, on a more technical level, different metronome devices (subdivision, audio click, leader only with click and other following by ear-sight, etc). I would have experimented also with more daring speeds of solo swaps. On a more distant/conceptual level, I would have liked to try other sonorities that remind me of swarming. Next time, I reckon…
Click here to download the dfscore for Multitudes Synchrones.
[…] look at dfscore 2.0 (read Rod’s blog post about the upgrades he’s […]
[…] DFScore […]